
Mohammad Beigi
About Me
I am a second-year CS PhD student at University of California, Davis, advised by Prof. Lifu Huang. My research centers on improving the reasoning, alignment, and interpretability of large language models. Currently, I focus on developing mechanisms for robust reasoning and trustworthy alignment by detecting and mitigating reward hacking through adversarial auditing and inverse reinforcement learning, and by designing uncertainty-aware methods to enhance reasoning stability and reduce sycophancy. My goal is to make these models not only more capable, but also more reliable, transparent, and aligned with human intent.
Prior to starting my PhD, I completed my Masters at Virginia Tech, and obtained my BS from Sharif University of Technology.
If you’re interested in my research, would like to discuss relevant topics, or explore potential collaborations, please feel free to get in touch :) - I am best reached by email at mbeigi@ucdavis.edu.
Research Interests
- Reinforcement Learning, Inverse Reinforcement Learning, Reward Hacking
- Reasoning and Self-Training of Large Language Models
- Mechanistic Interpretability of Foundation Models
- Uncertainty Estimation and Quantification
News
- [Sept. 2025] Our paper, SMART, Sycophancy Mitigation Through Reinforcement Learning with Uncertainty-Aware Adaptive Reasoning Trajectories , is accepted to EMNLP 2025!
- [Feb. 2025] Our new survey on mechanistic interpretability for multi-modal foundation models is availble at arxiv!
- [Jan. 2025] Glad to share that our lab has moved to UC Davis!
- [Oct. 2024] Our new survey on uncertainty estimation and quantification of LLMs is availble at arxiv!
- [Sept. 2024] Our paper, InternalInspector, is accepted to EMNLP 2024!
- [May. 2024] Our paper, Navigating Dual Facet, on evaluating memory editing of LLMs is accepted to ACL 2024!
Publications
-
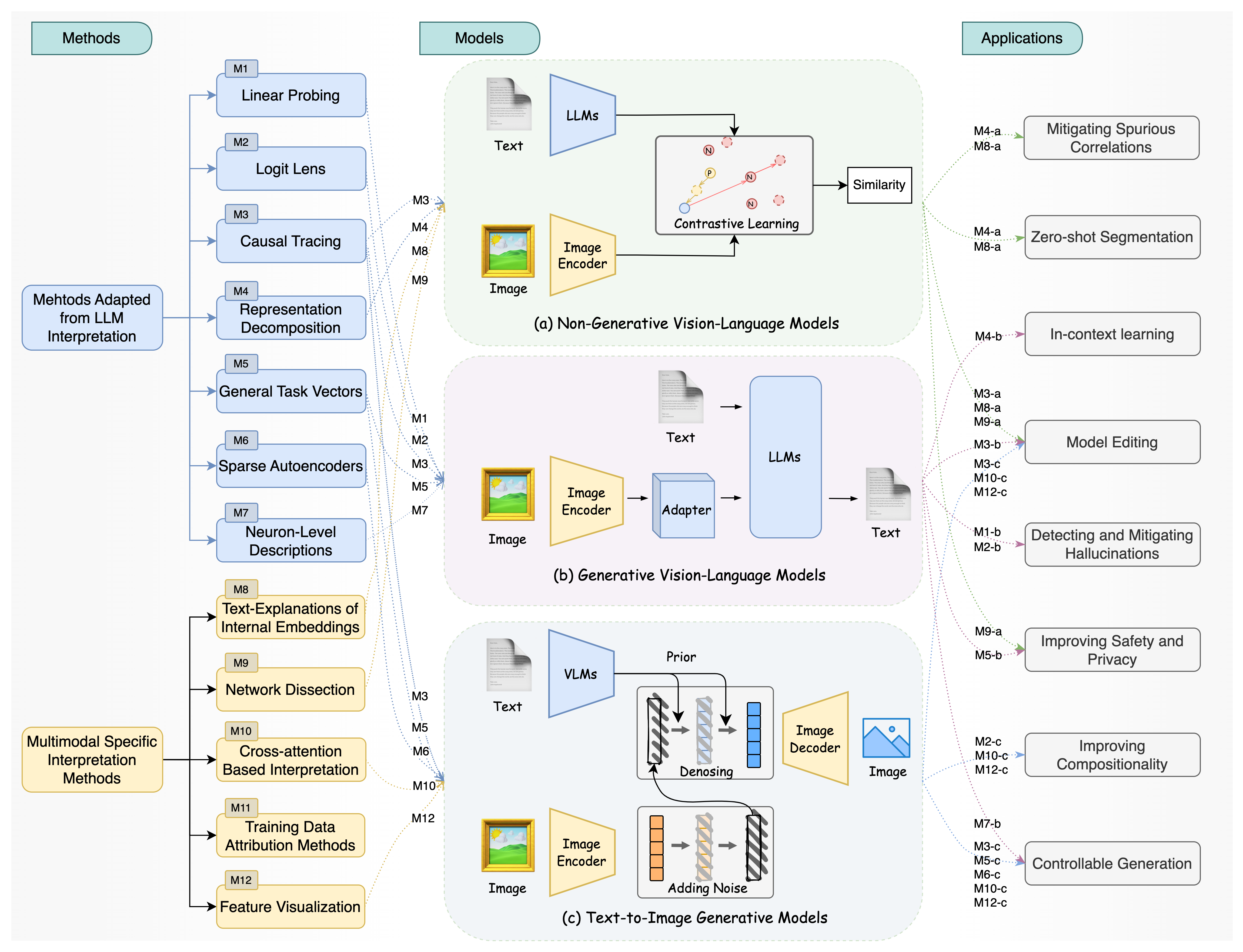 Pre-Print
Pre-Print
-
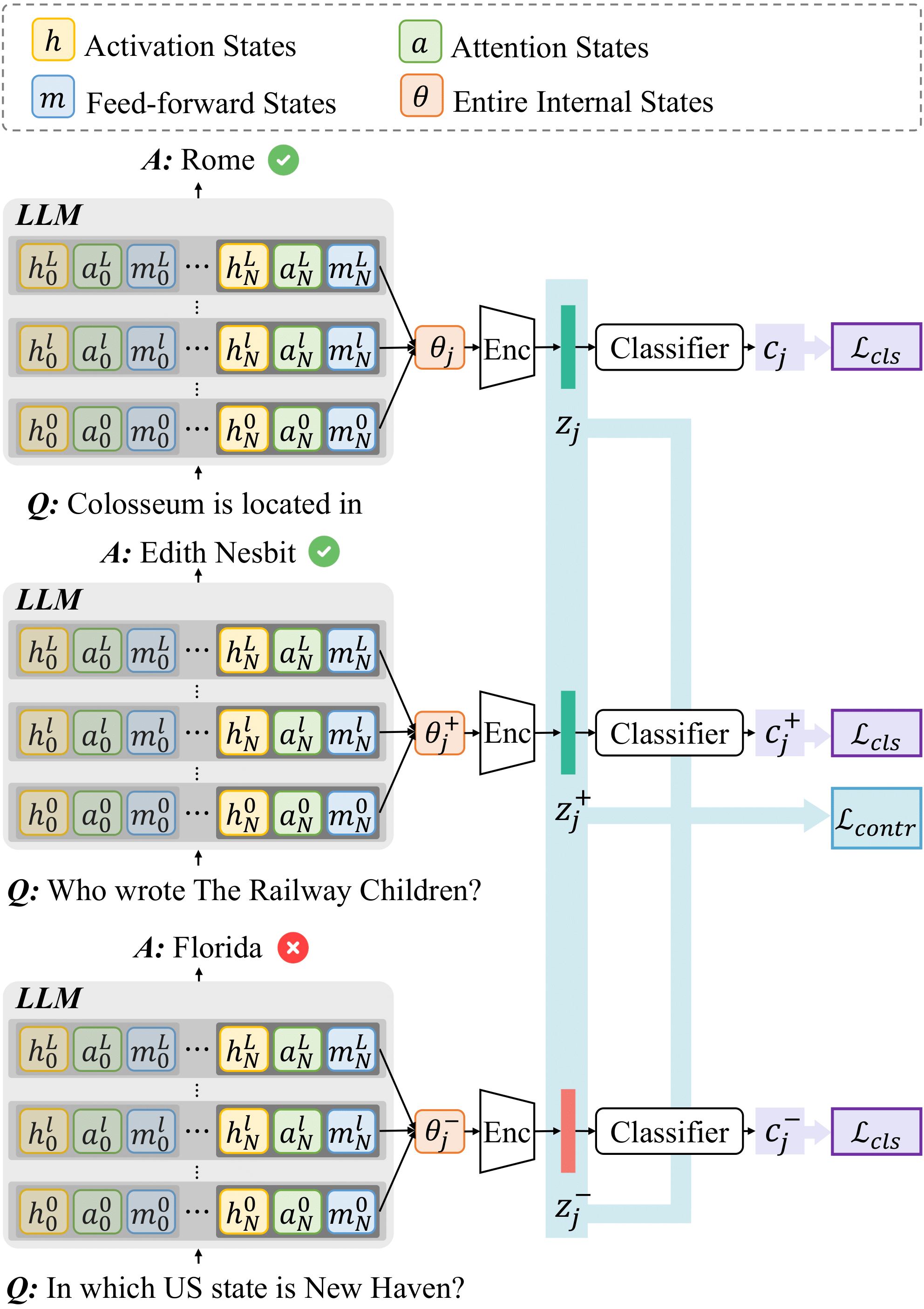 EMNLP 2024
The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)
EMNLP 2024
The 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) -
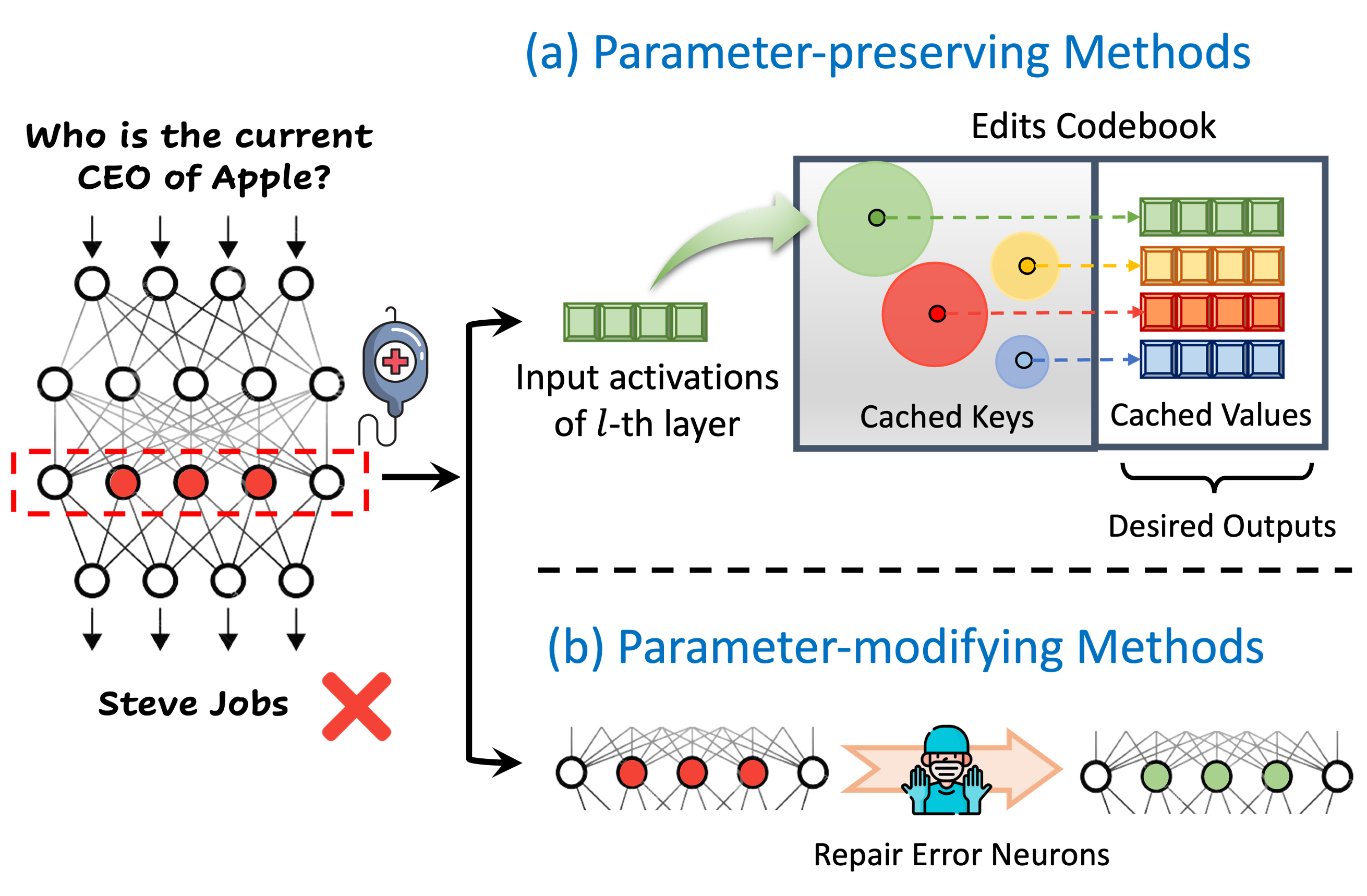 ACL 2024
The 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
ACL 2024
The 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
 EMNLP 2025
EMNLP 2025
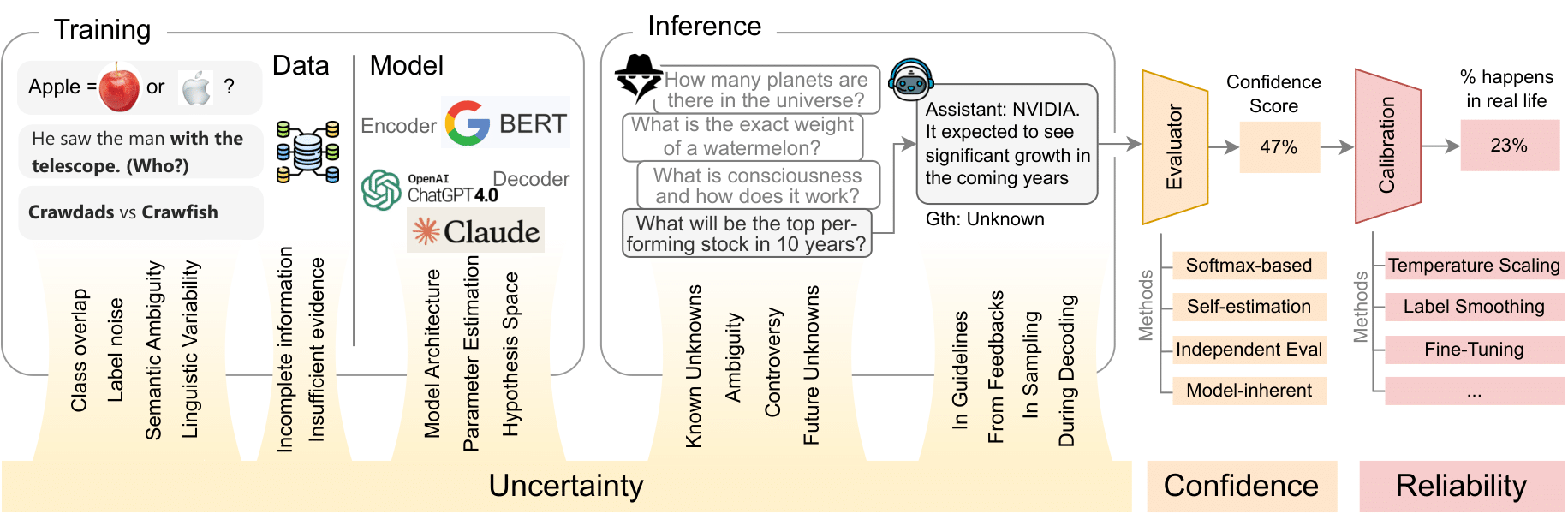 Pre-Print
Pre-Print
Services
Reviewer: ICLR 2025
Powered by Jekyll and Minimal Light theme.